Revizia anterioară Revizia următoare
| Fişierul intrare/ieşire: | lca.in, lca.out | Sursă | Arhiva educationala |
| Autor | Arhiva Educationala | Adăugată de |  Cella Florescu •cella.florescu Cella Florescu •cella.florescu |
| Timp execuţie pe test | 1.4 sec | Limită de memorie | 131072 kbytes |
| Scorul tău | N/A | Dificultate | N/A |
 Poti vedea testele pentru aceasta problema accesand atasamentele.
Poti vedea testele pentru aceasta problema accesand atasamentele.Vezi solutiile trimise | Statistici
Lowest Common Ancestor
Se dă un arbore cu N noduri, având rădăcina în nodul 1. Să se răspundă la M întrebări de forma: "Care este cel mai apropiat strămoş comun al nodurilor x şi y".
Date de intrare
Pe prima linie a fişierului de intrare lca.in se găsesc N şi M. Următoarea linie conţine N - 1 numere naturale, cel de-al i-lea număr reprezentând tatăl nodului i + 1 (nodul 1 fiind rădăcină nu are tată). Pe următoarele M linii se află câte 2 numere naturale, reprezentând nodurilor care definesc întrebările.
Date de ieşire
Fişierul de ieşire lca.out va conţine M linii, linia i conţinând răspunsul la întrebarea i.
Restricţii
- 1 ≤ N ≤ 100 000
- 1 ≤ M ≤ 2 000 000
Exemplu
| lca.in | lca.out |
|---|---|
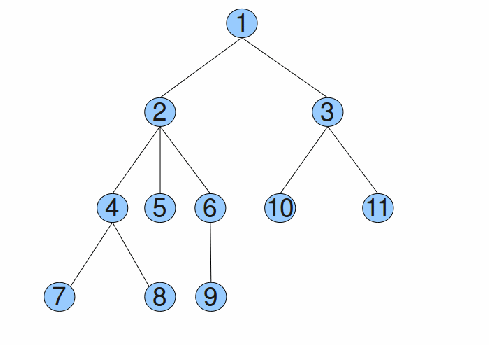
| 11 5 1 1 2 2 2 4 4 6 3 3 10 11 8 9 5 11 5 6 4 2 | 3 2 1 2 2 |
Explicaţie
Arborele din exemplu arată astfel:
O primă soluţie, care caută LCA-ul celor două noduri mergând "în sus" pe ramurile nodurilor până când acestea se intersectează, având complexitatea de ") , ar trebui să obţină 30 puncte şi se găseşte aici.
, ar trebui să obţină 30 puncte şi se găseşte aici.
O altă soluţie descrisă în acest articol, având complexitatea finală de ") , ar trebui să obţină 60 puncte. Aici se găseşte o sursă care se bazează pe această idee. Deşi nu este cea mai eficientă, avantajul acestei soluţii constă în faptul că se implementează foarte repede.
, ar trebui să obţină 60 puncte. Aici se găseşte o sursă care se bazează pe această idee. Deşi nu este cea mai eficientă, avantajul acestei soluţii constă în faptul că se implementează foarte repede.
O altă soluţie relativ uşor şi rapid de implementat în condiţii de concurs este cea care foloseşte ideea de la problema Strămoşi. Se reţine pentru fiecare nod strămoşul cu  nivele mai sus, unde k ia valori între
nivele mai sus, unde k ia valori între  şi
şi  . Astfel, pentru fiecare query, se aduce nodul de pe nivelul mai mare pe acelaşi nivel cu celălalt, după care se poate afla în timp logaritmic LCA-ul celor două noduri. Complexitatea finală este
. Astfel, pentru fiecare query, se aduce nodul de pe nivelul mai mare pe acelaşi nivel cu celălalt, după care se poate afla în timp logaritmic LCA-ul celor două noduri. Complexitatea finală este ") . Această soluţie ar trebui să obţină 60 puncte, iar sursa care se bazează pe această idee este aceasta.
. Această soluţie ar trebui să obţină 60 puncte, iar sursa care se bazează pe această idee este aceasta.
TODO Am înţeles. Dar din câte văd tu le aduci pe acelaşi nivel în timp liniar. Dacă ai un lanţ atunci nu ai nicio şansă să obţii complexitatea de care zici. Dovadă că în O(NlogN + Mlog2N) îmi merge mai repede.
UPDATE Exact asta mi se pare dubios, pentru că la mine Lmax este logaritm în baza 2 din înalţimea maximă a arborelui, iar eu am două foruri de la Lmax la 1. De altfel, testul pe care pică este testul 7, care este defapt un lanţ.
Soluţia care ar trebui să obţină 100 de puncte se bazează pe următoarea observaţie: „Cel mai apropiat strămoş comun a 2 noduri este nodul de nivel minim dintre primele apariţii ale nodurilor din query din reprezentarea Euler a arborelui.” În cazul de faţă, reprezentarea Euler a arborelui este următoarea, pe următorul rând găsindu-se nivelurile nodurilor:
| Reprezentarea Euler | 1 | 2 | 4 | 7 | 4 | 8 | 4 | 2 | 5 | 2 | 6 | 9 | 6 | 2 | 1 | 3 | 10 | 3 | 11 | 3 | 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Nivelul | 0 | 1 | 2 | 3 | 2 | 3 | 2 | 1 | 2 | 1 | 2 | 3 | 2 | 1 | 0 | 1 | 2 | 1 | 2 | 1 | 0 |
Pentru exemplificare, nodurile 8 şi 9 au cel mai apropiat strămoş comun nodul cu nivel minim din secvenţa 8 4 2 5 2 6 9, adică nodul 2, care are nivelul 1.
Pentru a implementa această soluţie, se folosesc arbori de intervale, având complexitatea ") , soluţie care ar trebui sa obţină 70 de puncte. Mai eficient, ţinând cont de restricţiile problemei, pentru determinarea minimului unei subsecvenţe se poate folosi RMQ. Astfel, complexitatea finală va fi
, soluţie care ar trebui sa obţină 70 de puncte. Mai eficient, ţinând cont de restricţiile problemei, pentru determinarea minimului unei subsecvenţe se poate folosi RMQ. Astfel, complexitatea finală va fi ") , această soluţie obţinând 100 de puncte. Dezavantajul acestei metode constă în faptul că se foloseşte
, această soluţie obţinând 100 de puncte. Dezavantajul acestei metode constă în faptul că se foloseşte ") memorie, ceea ce poate fi un impediment în anumite cazuri.
memorie, ceea ce poate fi un impediment în anumite cazuri.
O altă soluţie este algoritmul lui Tarjan care rezolvă query-urile offline, bazându-se pe structura de date mulţimi disjuncte. Are complexitatea de ") şi ar trebui să obţină 70 de puncte. O sursă care se bazează pe această idee este aceasta. Asemenea metodei cu RMQ, şi această metodă foloseşte o cantitate mai mare de memorie,
şi ar trebui să obţină 70 de puncte. O sursă care se bazează pe această idee este aceasta. Asemenea metodei cu RMQ, şi această metodă foloseşte o cantitate mai mare de memorie, ") care în anumite condiţii nu se încadrează limitei de memorie. Un alt dezavantaj în anumite cazuri este faptul că query-urile nu se parcurg în ordine, ci se rezolvă offline.
care în anumite condiţii nu se încadrează limitei de memorie. Un alt dezavantaj în anumite cazuri este faptul că query-urile nu se parcurg în ordine, ci se rezolvă offline.
Un articol ce explică foarte bine atât RMQ, cât şi LCA se găseşte pe TopCoder.
