
Ultimele insemnari
- Lot Informatică 2023
- "Adolescent Grigore Moisil" International Programming Contest
- Nitro NLP Hackaton - 2023
- Fmi No Stress11
- Retrospectiva Anului 2021
- Zilele Algoritmice Romanesti 2021
- "Adolescent Grigore Moisil" International Programming Contest
- Retrospectiva Anului 2020
- 98
- Nave Ordonate
Categorii
- algoritmiada (7)
- algoritmica (1)
- concursuri (11)
- doi la suta (1)
- Evenimente (7)
- facebook (1)
- Features (3)
- girl camp (2)
- Girls (2)
- Girls camp (2)
- girls programming camp (3)
- google (1)
- infoarena (6)
- internships (1)
- interviu (12)
- life the universe and everything (7)
- organizare (3)
- potw (31)
- preoni 2008 (3)
- probleme (9)
- Selectie Girls Programming Camp (1)
- statistici (1)
- stiri (76)
- video (6)
Blogroll
Coding Contest Byte: The Square Root Trick

We're starting a series of articles describing tricks useful in programming contests. Please keep the comments in English.
Being flexible and easy to code, the square root trick is pretty popular in the Romanian programming contests community. It even has a name: "jmenul lu Batog" which means Batog's trick :). Bogdan Batog introduced it to a few high school students more than ten years ago and the trick entered romanian coding contest folklore.
The idea is that we can use bucketing or a two level tree as some people call it to improve naive data structures or algorithms. The square root part appears when we minimize the function n/x + x, we'll see more about that later on.
Let’s check out a few problems that explain how the trick works.
Range Sum
Given A, an n elements array, implement a data structure for point updates and range sum queries:
- update(i, x): A[i] := x,
- query(lo, hi) returns A[lo] + A[lo+1] + .. + A[hi].
The naive solution uses an array. It takes O(1) time for an update and O(hi - lo) = O(n) for the range sum.
A more efficient solution splits the array into length k slices and stores the slice sums in an array S.
The update takes constant time, because we have to update the value for A and the value for the corresponding S.
The query is interesting. The elements of the first and last slice (partially contained in the queried range) have to be traversed one by one, but for slices completely contained in our range we can use the values in S directly and get a performance boost.
Here is an update example:
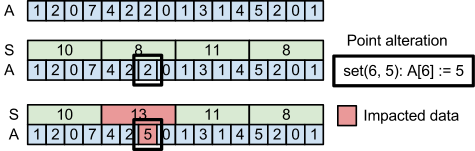
In update(6, 5) we have to change A[6] to 5 which results in changing the value of S[1] to keep S up to date.
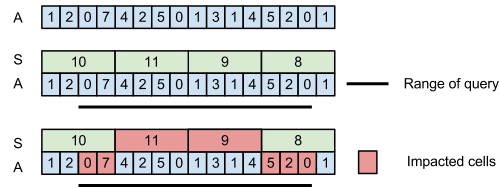
query(2, 14) = A[2] + A[3]+
(A[4] + A[5] + A[6] + A[7]) +
(A[8] + A[9] + A[10] + A[11]) +
A[12] + A[13] + A[14]
= A[2] + A[3] +
S[1] + S[2] +
A[12] + A[13] + A[14]
= 0 + 7 + 11 + 9 + 5 + 2 + 0
= 34Here's how the code looks:
def update(S, A, i, k, x):
S[i/k] = S[i/k] - A[i] + x
A[i] = x
def query(S, A, lo, hi, k):
s = 0
i = lo
while (i + 1) % k != 0 and i <= hi:
s += A[i]
i += 1
while i + k <= hi:
s += S[i/k]
i += k
while i <= hi:
s += A[i]
i += 1
return sEach query takes on average k/2 + n/k + k/2 = k + n/k time. This is minimized for k = sqrt(n). So we get a O(sqrt(n)) time complexity query.
This trick also works for other associative operations, like: min, gcd, product etc.
Nearest neighbour
Given a set S of n points and a query point p, find the point in S closest to p.
For uniformly distributed points, a good strategy is to represent the space as a grid and maintain a list of inner points for each cell. For a given query point, we can check the cell the point falls into and its neighbouring cells. For a sqrt(n) * sqrt(n) grid we’ll have one point per cell, on average. On average, finding the point in S closest to p, requires traversing a constant number of cells.
Longest common subsequence
Given two strings A (n characters) and B (m characters), find their longest common subsequence. (eg. The longest common sub sequence for abcabc and abcbcca is abcbc.)
There is a standard dynamic programming solution which uses an array best[i][j] to mean the longest common sub sequence for A[0:i] and B[0:j], computed as below:
if A[i] == B[j]:
best[i][j] = 1 + best[i - 1][j - 1]
else:
best[i][j] = max(best[i-1][j], best[i][j-1])This algorithm takes O(nm) time and only O(n) space, since to compute a row you just need the previous row.
If you must return the actual sub sequence this doesn't work. You can keep an array of parent pointers, so that for each state (i, j) you know the previous state in the solution. The longest sub sequence corresponds to a path from (n-1, m-1) to (0, 0) on the parent matrix. This solution takes O(nm) space.
Let's try to use less memory. We solve the problem once and save every kth row from the best matrix and from the parent matrix.
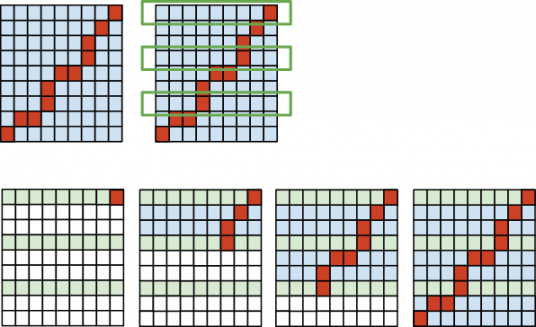 We can start from the last saved row to compute the solution path from row [n/k] * k to row n - 1. Then we go downwards to compute the part of the solution between the row ik and the row (i+1)k . Computing part of the path between row ik and row (i+1)k takes O(km) space and O(km) time. Computing the whole path takes O(n/k (km)) = O(nm) time and O(km) space. Saving the first pass rows takes O([n/k]m) memory. Again, we minimize total memory usage by using k = sqrt(n). This solution takes O(sqrt(n)m) memory.
We can start from the last saved row to compute the solution path from row [n/k] * k to row n - 1. Then we go downwards to compute the part of the solution between the row ik and the row (i+1)k . Computing part of the path between row ik and row (i+1)k takes O(km) space and O(km) time. Computing the whole path takes O(n/k (km)) = O(nm) time and O(km) space. Saving the first pass rows takes O([n/k]m) memory. Again, we minimize total memory usage by using k = sqrt(n). This solution takes O(sqrt(n)m) memory.
Caveats
There are more efficient solutions for the previous problems, but those are a bit more involved. The square root trick has a good balance between added complexity and algorithm speedup.
Additional problems
- (Josephus Problem) n people numbered from 1 to n sit in a circle and play a game. Starting from the first person and every kth person is eliminated. Write an algorithm that prints out the order in which people are eliminated.
- (Level Ancestor) You are given an tree of size n. ancestor(node, levelsUp) finds the node’s ancestor that is levelsUp steps up. For example, ancestor(node, 1) returns the father and ancestor(node, 2) returns the grandfather. Implement ancestor(node, levelsUp) efficiently. ( O(sqrt(n)) per query)
- (Range Median) You are given an array of size n. Implement a data structure to perform update operations a[i] = k and range median operations efficiently. The range median query, median(l, r) returns the median element of the sorted subsequence a[l..r]. O(log(n)) per update and
O(sqrt(n)log(n))O(sqrt(n)log(n)log(U)) per query
