Revizia anterioară Revizia următoare
Tabele hash - prezentare detaliata
 Acest articol a fost adăugat de Acest articol a fost adăugat de  Claudia Cardei •cyber Claudia Cardei •cyberIntră aici dacă doreşti să scrii articole sau află cum te poţi implica în celelalte proiecte infoarena! |
(Categoria Structuri de date, Autor Catalin Francu, preluat din cartea "Psihologia concursurilor de informatica")
In multe aplicatii lucram cu structuri mari de date in care avem nevoie sa facem cautari, inserari, modificari si stergeri. Aceste structuri pot fi vectori, matrice, liste etc. In cazurile mai fericite ale vectorilor, acestia pot fi sortati, caz in care localizarea unui element se face prin metoda injumatatirii intervalului, adica in timp logaritmic. Chiar daca nu avem voie sa sortam vectorul, tot se pot face anumite optimizari care reduc foarte mult timpul de cautare. De exemplu, probabil ca multi dintre cititori au idee despre ce inseamna indexarea unei baze de date. Daca avem o baza de date cu patru elemente de tip string, si anume
B = ("bac", "zugrav", "abac", "zarva")
putem construi un vector Ind care sa ne indice ordinea in care s-ar cuveni sa fie asezate cuvintele in vectorul sortat. Ordinea alfabetica (din cartea de telefon) a cuvintelor este: "abac", "bac", "zarva", "zugrav", deci vectorul Ind este:
Ind = (3, 1, 4, 2)
semnificand ca primul cuvant din vectorul sortat ar trebui sa fie al treilea din vectorul B, respectiv "abac", si asa mai departe. In felul acesta am obtinut un vector sortat, care presupune o indirectare a elementelor. Vectorul sortat este
B' = (B(Ind(1)), B(Ind(2)), B(Ind(3)), B(Ind(4)).
Aceasta operatie se numeste indexare. Ce-i drept, constructia vectorului Ind nu se poate face intr-un timp mai bun decat O(N log N), dar dupa ce acest lucru se face (o singura data, la inceputul programului), cautarile se pot face foarte repede. Daca pe parcurs se fac adaugari sau stergeri de elemente in/din baza de date, se va pierde catva timp pentru mentinerea indexului, dar in practica timpul acesta este mult mai mic decat timpul care s-ar pierde cu cautarea unor elemente in cazul in care vectorul ar fi neindexat. Nu vom intra in detalii despre indexare, deoarece nu acesta este obiectul capitolului de fata.
In unele situatii nu se poate face nici indexarea structurii de date. Sa consideram cazul unui program care joaca sah. Numarul de pozitii posibile ale pieselor pe tabla de sah este mult prea mare. Nu poate fi vorba nici de retinerea tuturor, cu atat mai putin de indexarea lor. In esenta, modul de functionare al acestui program se reduce la o rutina care primeste o pozitie pe tabla si o variabila care indica daca la mutare este albul sau negrul, rutina intorcand cea mai buna mutare care se poate efectua din acea pozitie. Majoritatea programelor de sah incep sa expandeze respectiva pozitie, examinand tot felul de variante ce pot decurge din ea si alegand-o pe cea mai promitatoare, asa cum fac si jucatorii umani. Pozitiile analizate, fiind mult mai putine decat cele posibile, sunt stocate in memorie sub forma unei liste.
Sa ne inchipuim acum urmatoarea situatie. Este posibil ca, prin expandarea unei configuratii initiale a tablei sa se ajunga la aceeasi configuratie finala pe doua cai diferite. Spre exemplu, daca albul muta intai calul la f3, apoi nebunul la c4, pozitia rezultata va fi aceeasi ca si cand s-ar fi mutat intai nebunul si apoi calul (considerand bineinteles ca negrul da in ambele situatii aceeasi replica). Daca configuratia finala a fost deja analizata pentru prima varianta, este inutil sa o mai analizam si pentru cea de-a doua, pentru ca rezultatul (concluzia la care se va ajunge) va fi exact acelasi. Dar cum isi poate da programul seama daca pozitia pe care are de gand s-o analizeze a fost analizata deja sau nu ?
Cea mai simpla metoda este o scanare a listei de configuratii examinate din memorie. Daca in aceasta lista se afla pozitia curenta de analizat, inseamna ca ea a fost deja analizata si vom renunta la ea. Daca nu, o vom analiza acum. Ideea in mare a algoritmului este:
procedura Analizeaza(Pozitie P)
cauta P in lista de pozitii deja analizate
daca P nu exista in lista
expandeaza P si afla cea mai buna mutare M
adauga P la lista de pozitii analizate
intoarce M
altfel
intoarce valoarea M atasata pozitiei P gasite in lista
sfarsitNu vom insista asupra a cum se expandeaza o pozitie si cum se calculeaza efectiv cea mai buna mutare. Noi ne vom interesa de un singur aspect, si anume cautarea unei pozitii in lista. Tehnica cea mai "naturala" este o parcurgere a listei de la cap la coada, comparand pe rand pozitia cautata cu fiecare pozitie din lista. Daca lista are memorate N pozitii, atunci in cazul unei cautari cu succes (pozitia este gasita), numarul mediu de comparatii facute este N/2, iar numarul cel mai defavorabil ajunge pana la N. In cazul unei cautari fara succes (pozitia nu exista in lista), numarul de comparatii este intotdeauna N. De altfel, cazul cautarii fara succes este mult mai frecvent pentru problema jocului de sah, unde numarul de pozitii posibile creste exponential cu numarul de mutari. Acelasi numar de comparatii il presupune si stergerea unei pozitii din lista (care presupune intai gasirea ei) si adaugarea (care presupune ca pozitia de adaugat sa nu existe deja in lista).
Pentru imbunatatirea practica a acestui timp sunt folosite tabelele de dispersie sau tabelele hash (engl. hash = a toca, tocatura). Mentionam de la bun inceput ca tabelele hash nu au nicio utilitate din punct de vedere teoretic. Daca suntem rau intentionati, este posibil sa gasim exemple pentru care cautarea intr-o tabela hash sa dureze la fel de mult ca intr-o lista simplu inlantuita, respectiv O(N). Dar in practica timpul cautarii si al adaugarii de elemente intr-o tabela hash coboara uneori pana la O(1), iar in medie scade foarte mult (de mii de ori).
Iata despre ce este vorba. Sa presupunem pentru inceput ca in loc de pozitii pe tabla de sah, lista noastra memoreaza numere intre 0 si 999. In acest caz, tabela hash ar fi un simplu vector H cu 1000 de elemente booleene. Initial, toate elementele lui H au valoarea False (sau 0). Daca numarul 473 a fost gasit in lista, nu avem decat sa setam valoarea lui H(473) la True (sau 1). La o noua aparitie a lui 473 in lista, vom examina elementul H(473) si, deoarece el este True, inseamna ca acest numar a mai fost gasit. Daca dorim stergerea unui element din hash, vom reseta pozitia corespunzatoare din H. Practic, avem de-a face cu un exemplu rudimentar de ceea ce se cheama functie de dispersie, adica h(x)=x. O proprietate foarte importanta a acestei functii este injectivitatea; este imposibil ca la doua numere distincte sa corespunda aceeasi intrare in tabela. Sa incercam o reprezentare grafica a metodei:
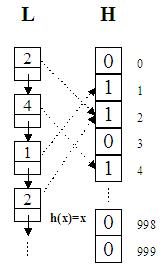
Iata primul set de proceduri de gestionare a unui Hash.
const int M = 1000;
typedef int DataType;
typedef DataType Hash[M];
Hash H;
void InitHash1(Hash H) {
for (int i=0; i<M; H[i++]=0);
}
inline int h(DataType K) {
return K;
}
int Search1(Hash H, DataType K) {
// Intoarce -1 daca elementul nu exista in hash
// sau indicele in hash daca el exista
return H[h(K)] ? h(K) : -1;
}
void Add1(Hash H, DataType K) {
H[h(K)]=1;
}
void Delete1(Hash H, DataType K) {
H[h(K)]=0;
}Prin "numar de intrari" in tabela se intelege numarul de elemente ale vectorului H; in general, orice tabela hash este un vector. Pentru ca functiile sa fie cat mai generale, am dat tipului de data int un nou nume DataType. In principiu, tabelele Hash se aplica oricarui tip de date. In realitate, fenomenul este tocmai cel invers: orice tip de date trebuie "convertit" printr-o metoda sau alta la tipul de date int, iar functia de dispersie primeste ca parametru un intreg. Functiile hash prezentate in viitor nu vor mai lucra decat cu variabile de tip intreg. Vom vorbi mai tarziu despre cum se poate face conversia. Acum sa generalizam exemplul de mai sus.
Intr-adevar, cazul anterior este mult prea simplu. Sa ne inchipuim de pilda ca in loc de numere mai mici ca 1000, avem numere de pana la 2.000.000.000. In aceasta situatie posibilitatea de a reprezenta tabela ca un vector caracteristic iese din discutie. Numarul de intrari in tabela este de ordinul miilor, cel mult al zecilor de mii, deci cu mult mai mic decat numarul total de chei (numere) posibile. Ce avem de facut? Am putea incerca sa adaugam un numar K intr-o tabela cu M intrari (numerotate de la 0 la M-1) pe pozitia K mod M, adica h(K) = K mod M. Care va fi insa rezultatul? Functia h isi va pierde proprietatea de injectivitate, deoarece mai multor chei le poate corespunde aceeasi intrare in tabela, cum ar fi cazul numerelor 1234 si 2001234, ambele dand acelasi rest la impartirea prin M=1000. Nu putem avea insa speranta de a gasi o functie injectiva, pentru ca atunci numarul de intrari in tabela ar trebui sa fie cel putin egal cu numarul de chei distincte. Vrand-nevrand, trebuie sa rezolvam coliziunile (sau conflictele) care apar, adica situatiile cand mai multe chei distincte sunt repartizate la aceeasi intrare.
Vom reveni ulterior la oportunitatea alegerii functiei modul si a numarului de 1000 de intrari in tabela. Deocamdata vom folosi aceste date pentru a explica modul de functionare a tabelei hash pentru functii neinjective. Sa presupunem ca avem doua chei K1 si K2 care sunt repartizate de functia h la aceeasi intrare X, adica h(K1)=h(K2)=X. Solutia cea mai comoda este ca H(X) sa nu mai fie un numar, ci o lista liniara simplu inlantuita care sa contina toate cheile gasite pana acum si repartizate la aceeasi intrare X. Prin urmare vectorul H va fi un vector de liste:
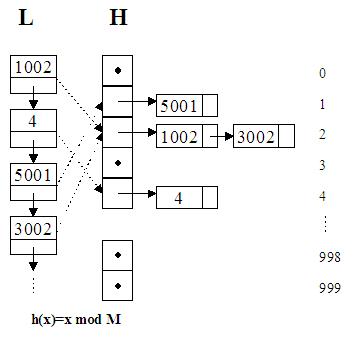
Sa analizam acum complexitatea noilor proceduri de cautare, adaugare si stergere. Cautarea nu se va mai face in toata lista, ci numai in lista corespunzatoare din H. Altfel spus, o cheie K se va cauta numai in lista H(h(K)), deoarece daca cheia K a mai aparut, ea a fost in mod sigur repartizata la intrarea H(h(K)). De aceea, cautarea poate ajunge, in cazul cel mai defavorabil cand toate cheile din lista se repartizeaza la aceeasi intrare in hash, la o complexitate O(N). Daca reusim insa sa gasim o functie care sa distribuie cheile cat mai aleator, timpul de intrare se va reduce de M ori. Avantajele sunt indiscutabile pentru M=10000 de exemplu.
Intrucat operatiile cu liste liniare sunt in general cunoscute, nu vom insista asupra lor. Prezentam aici numai adaugarea si cautarea, lasandu-va ca tema scrierea functiei de stergere din tabela.
#include <stdio.h>
#include <stdlib.h>
const int M = 1000;
typedef struct List_ {
long P;
struct List_ *Next;
} List;
typedef List* Hash[M];
Hash H;
void InitHash2(Hash H){
for (int i=0; i<M; H[i++]=NULL);
}
int h2(int K) {
return K % M;
}
int Search2(Hash H, int K) {
// Intoarce 0 daca elementul nu exista in hash
// sau 1 daca el exista
List *L;
for (L=H[h2(K)]; L && (L->P != K); L = L->Next);
return L!=NULL;
}
void Add2(Hash H, int K) {
List *L = (List *) malloc(sizeof(List));
L->P = K;
L->Next = H[h2(K)];
H[h2(K)] = L;
}Am spus ca functiile de dispersie sunt concepute sa lucreze numai pe date de tip intreg; celelalte tipuri de date trebuie convertite in prealabil la tipuri de date intregi. Iata cateva exemple:
- Variabilele de tip string pot fi transformate in numere in baza 256 prin inlocuirea fiecarui caracter cu codul sau ASCII. De exemplu, sirul "abac" poate fi privit ca un numar de 4 cifre in baza 256, si anume numarul (97 98 97 99). Conversia lui in baza 10 se face astfel:
X = ((97 * 256 + 98) * 256 + 97) * 256 + 99 = 1 633 837 411
Pentru stringuri mai lungi, rezulta numere mai mari. Uneori, ele nici nu mai pot fi reprezentate cu tipurile de date ordinare. Totusi, acest dezavantaj nu este suparator, deoarece majoritatea functiilor de dispersie presupun o impartire cu rest, care, indiferent de marimea numarului de la intrare, produce un numar controlabil.
- Variabilele de tip data se pot converti la intreg prin formula:
X = A * 366 + L * 31 + Z
unde A, L si Z sunt respectiv anul, luna si ziua datei considerate. De fapt, aceasta functie aproximeaza numarul de zile scurse de la inceputul secolului I. Ea nu are pretentii de exactitate (ca dovada, toti anii sunt considerati a fi bisecti si toate lunile a avea 31 de zile), deoarece s-ar consuma timp inutil cu calcule mai sofisticate, fara ca dispersia insasi sa fie imbunatatita cu ceva. Conditia care trebuie neaparat respectata este ca functia de conversie data  intreg sa fie injectiva, adica sa nu se intample ca la doua date D1 si D2 sa li se ataseze acelasi intreg X; daca acest lucru se intampla, pot aparea erori la cautarea in tabela (de exemplu, se poate raporta gasirea datei D1 cand de fapt a fost gasita data D2). Pentru a respecta injectivitatea, s-au considerat coeficientii 366 si 31 in loc de 365 si 30. Daca numarul de zile scurse de la 1 ianuarie anul 1 d.H. ar fi fost calculat cu exactitate, functia de conversie ar fi fost si surjectiva, dar, dupa cum am mai spus, acest fapt nu prezinta interes.
intreg sa fie injectiva, adica sa nu se intample ca la doua date D1 si D2 sa li se ataseze acelasi intreg X; daca acest lucru se intampla, pot aparea erori la cautarea in tabela (de exemplu, se poate raporta gasirea datei D1 cand de fapt a fost gasita data D2). Pentru a respecta injectivitatea, s-au considerat coeficientii 366 si 31 in loc de 365 si 30. Daca numarul de zile scurse de la 1 ianuarie anul 1 d.H. ar fi fost calculat cu exactitate, functia de conversie ar fi fost si surjectiva, dar, dupa cum am mai spus, acest fapt nu prezinta interes.
- Analog, variabilele de tip ora se pot converti la intreg cu formula:
X = (H * 60 + M) * 60 + S
unde H, M si S sunt respectiv ora, minutul si secunda considerate, sau cu formula
X = ((H * 60 + M) * 60 + S) * 100
daca se tine cont si de sutimile de secunda. De data aceasta, functia este surjectiva (oricarui numar intreg din intervalul 0 - 8.639.999 ii corespunde in mod unic o ora).
- In majoritatea cazurilor, datele sunt structuri care contin numere si stringuri. O buna metoda de conversie consta in alipirea tuturor acestor date si in convertirea la baza 256. Caracterele se convertesc prin simpla inlocuire cu codul ASCII corespunzator, iar numerele prin convertirea in baza 2 si taierea in "bucati" de cate opt biti. Rezulta numere cu multe cifre (prea multe chiar si pentru tipul longint), care sunt supuse unei operatii de impartire cu rest. Functia de conversie trebuie sa fie injectiva. De exemplu, in cazul tablei de sah despre care am amintit mai inainte, ea poate fi transformata intr-un vector cu 64 de cifre in baza 16, cifra 0 semnificand un patrat gol, cifrele 1-6 semnificand piesele albe (pion, cal, nebun, turn, regina, rege), iar cifrele 7-12 semnificand piesele negre. Prin trecerea acestui vector in baza 256, rezulta un numar cu 32 de cifre. La acesta se mai pot adauga alte cifre, respectiv partea la mutare (0 pentru alb, 1 pentru negru), posibilitatea de a efectua rocada mica/mare de catre alb/negru, numarul de mutari scurse de la inceputul partidei si asa mai departe.
Vom termina prin a prezenta doua functii de dispersie foarte des folosite.
Metoda impartirii cu rest
Despre aceasta metoda am mai vorbit. Functia hash este: h(x) = x mod M unde M este numarul de intrari in tabela. Problema care se pune este sa-l alegem pe M cat mai bine, astfel incat numarul de coliziuni pentru oricare din intrari sa fie cat mai mic. De asemenea, trebuie ca M sa fie cat mai mare, pentru ca media numarului de chei repartizate la aceeasi intrare sa fie cat mai mica. Totusi, experienta arata ca nu orice valoare a lui M este buna.
De exemplu, la prima vedere s-ar putea spune ca o buna valoare pentru M este o putere a lui 2, cum ar fi 1024, pentru ca operatia de impartire cu rest se poate face foarte usor in aceasta situatie. Totusi, functia h(x) = x mod 1024 are un mare defect: ea nu tine cont decat de ultimii 10 biti ai numarului x. Daca datele de intrare sunt numere in mare majoritate pare, ele vor fi repartizate in aceeasi proportie la intrarile cu numar de ordine par, pentru ca functia h pastreaza paritatea. Din aceleasi motive, alegerea unei valori ca 1000 sau 2000 nu este prea inspirata, deoarece tine cont numai de ultimele 3-4 cifre ale reprezentarii zecimale. Multe valori pot da acelasi rest la impartirea prin 1000. De exemplu, daca datele de intrare sunt anii de nastere ai unor persoane dintr-o agenda telefonica, iar functia h(x)=x mod 1000, atunci majoritatea cheilor se vor ingramadi (termenul este sugestiv) intre intrarile 920 si 990, restul ramanand nefolosite.
Practic, trebuie ca M sa nu fie un numar rotund in nicio baza aritmetica, sau cel putin nu in bazele 2 si 10. O buna alegere pentru M sunt numerele prime care sa nu fie apropiate de nicio putere a lui 2. De exemplu, in locul unei tabele cu M=10000 de intrari, care s-ar comporta dezastruos, putem folosi una cu 9973 de intrari. Chiar si aceasta alegere poate fi imbunatatita; intre puterile lui 2 vecine, respectiv 8192 si 16384, se poate alege un numar prim din zona 11000-12000. Risipa de memorie de circa 1000-2000 de intrari in tabela va fi pe deplin compensata de imbunatatirea cautarii.
Metoda inmultirii
Pentru aceasta metoda functia hash este h(x) = [M * {x*A}]. Aici A este un numar pozitiv subunitar, 0 < A < 1, iar prin {x*A} se intelege partea fractionara a lui x*A, adica x*A - [x*A]. De exemplu, daca alegem M = 1234 si A = 0.3, iar x = 1997, atunci avem h(x) = [1234 * {599.1}] = [1234 * 0.1] = 123. Se observa ca functia h produce numere intre 0 si M-1. Intr-adevar 0 ≤ {x*A} < 1  0 ≤ M * {x*A} < M.
0 ≤ M * {x*A} < M.
In acest caz, valoarea lui M nu mai are o mare importanta. O putem deci alege cat de mare ne convine, eventual o putere a lui 2. In practica, s-a observat ca dispersia este mai buna pentru unele valori ale lui A si mai proasta pentru altele. Donald Knuth propune valoarea  .
.
Ca o ultima precizare necesara la acest capitol, mentionam ca functia de cautare e bine sa nu intoarca pur si simplu 0 sau 1, dupa cum cheia cautata a mai aparut sau nu inainte intre datele de intrare. E recomandabil ca functia sa intoarca un pointer la zona de memorie in care se afla prima aparitie a cheii cautate. Vom da acum un exemplu in care aceasta valoare returnata este utila. Daca, in cazul prezentat mai sus al unui program de sah, se ajunge la o anumita pozitie P dupa ce albul a pierdut dreptul de a face rocada, aceasta pozitie va fi retinuta in hash. Retinerea nu se va face nicidecum efectiv (toata tabla), pentru ca s-ar ocupa foarte multa memorie. Se va memora in loc numai un pointer la pozitia respectiva din lista de pozitii analizate. Pe langa economia de memorie in cazul cheilor de mari dimensiuni, mai exista si alt avantaj. Sa ne inchipuim ca, analizand in continuare tabla, programul va ajunge la aceeasi pozitie P, dar in care albul are inca dreptul de a face rocada. E limpede ca aceasta varianta este mai promitatoare decat precedenta, deoarece albul are o libertate mai mare de miscare. Se impune deci fie stergerea vechii pozitii P din lista si adaugarea noii pozitii, fie modificarea celei vechi prin setarea unei variabile suplimentare care indica dreptul albului de a face rocada. Aceasta modificare este usor de facut, intrucat cautarea in hash va returna chiar un pointer la pozitia care trebuie modificata. Bineinteles, in cazul in care pozitia cautata nu se afla in hash, functia de cautare trebuie sa intoarca NULL.
In incheiere, prezentam un exemplu de functie de dispersie pentru cazul tablei de sah.
const int M = 9973; // Numarul de "intrari".
typedef struct {
char b_T[8][8]; // Tabla de joc, cu 0 <= T[i][j] <= 12.
char b_CastleW, b_CastleB; // Ultimii doi biti ai lui b_CastleW
// indica daca albul are dreptul de a
// efectua rocada mare, respectiv pe cea
// mica. Analog pentru b_CastleB.
char b_Side; // 0 sau 1, dupa cum la mutare este albul.
// sau negrul.
char b_EP; // 0..8, indicand coloana (0..7) pe care
// partea la mutare poate efectua o
// captura "en passant". 8 indica ca nu
// exista aceasta posibilitate.
int b_NMoves; // Numarul de mutari efectuate.
} Board;
Board B;
int h3(Board *B) {
int i, j;
// Valoarea initiala a lui S este un numar pe 17 biti care
// inglobeaza toate variabilele suplimentare pe langa T.
// S se va lua apoi modulo M.
long S = (B->b_NMoves // 8 biti
+(B->b_CastleW << 8) // 2 biti
+(B->b_CastleB << 10) // 2 biti
+(B->b_Side << 12) // 1 bit
+(B->b_EP << 13)) % M; // 4 biti
for (i=0; i<=7; i++)
for (j=0; j<=7; j++) {
S = (16*S + B->b_T[i][j]) % M;
}
return S;
}Teme pentru acasa
Iata si o scurta lista de probleme ce se rezolva eficient folosind tabelele hash:
